How Muon Lost Its Geometry
Muon is a new optimizer that has become quite popular recently. It is the first optimizer since Adam to be adopted by very large scale training runs (> 1T parameter LLMs). Its construction is theoretically motivated, and it's a breath of fresh air in the deep learning world where most choices are heuristic-based and empirical An iconic example is Noam Shazeer’s SwiGLU proposal, where he wrote that “we attribute its success, as all else, to divine benevolence.” .
In this blog, we will try to follow the popularization of Muon and give an account of how we think a scaling factor "bug" crept in to basically all implementations of Muon. This eventually made its way into very large scale training runs like Kimi-K2 and DeepSeek-V4, and we'll provide evidence for why it made ugly patches like MuonClip necessary. The theoretically correct way of doing this was already described by Jeremy Bernstein, one of the key authors of Muon and related ideas (who now works at Thinking Machines), but somehow the community seems to have overlooked this.
During the popularization of Muon, it seems to have accidentally lost is its maximal-update geometry Maximal update parameterization (µP) is a scaling rule for neural networks that keeps activations and update-induced activation changes comparable as width changes. In LLM training, it is used to tune hyperparameters at small scale and transfer them to larger models. : the scaling rule that makes an optimizer step produce the right-size perturbation in activation space. This was the reason we got interested in Muon in the first place. Neural networks used to model biomolecular space, such as AlphaFold3 architectures, have all sorts of layers: down-projections, up-projections, gates, pair updates, attention blocks, and geometry modules. It is very likely that the global learning rate in these models is an uneasy compromise between many layers that each want a different effective learning rate. If maximal-update parameterization were built into Muon correctly, we thought it might fix a lot of the quiet numerical issues in these networks.
Before we begin, we must give due credit to Jeremy Bernstein, whose blog post "Deriving Muon" is the only reason we were able to understand Muon's theoretical foundations well enough to notice something was off in the implementations. This also saved us from pretty nasty easter eggs in our codebase - silent numerical issues that would have sat in our model training stack which we probably never would have found.
A series of unfortunate events
Muon went from a training trick in CIFAR and NanoGPT speedruns to training trillion-parameter frontier models in about 18 months. That's quite impressive. This likely also means that people haven't quite dialed in how to work with it properly, iron out issues, make it efficient, etc.
We will describe the timeline that seems to have introduced the problematic scaling factor messing up the maximal update property.
Speedrun implementation tries to be like Adam
The Muon authors design an optimizer that takes each SGD-momentum update matrix and replaces it with its nearest orthogonal matrix via a Newton-Schulz iteration: MomentUm Orthogonalized by Newton-Schulz, or Muon. The design of Muon draws from Shampoo and Bernstein's modular-norm work, and uses a cute trick to do fast gradient orthogonalization on GPUs. In Keller's write-up, dropping it in for AdamW sets a new NanoGPT speedrun record, about 35% faster, and a quicker CIFAR-10 record. It then holds the NanoGPT crown and resists being displaced by AdamW. Using a speedrun to legitimize Muon is quite clever, and Keller deserves the credit for it. Optimizer research is a graveyard of ideas and papers that claim to improve on Adam but fail to do so in production. A speedrun is a self-correcting mechanism for this, since anyone can tune the Adam baseline. However, speedruns at a small scale also have an Achilles heel - they don't take into account most of the scaling law component of modern LLMs, hyperparameter transfer considerations, distributed scaling etc. Most things that are either good enough or look great at the small scale don't look so good at a large scale.
The first scaling-factor issue appears in one of the speedrun entries. One of the speedrun entries, in an attempt to make Muon more "normalized" like AdamW (which uses elementwise correction terms for both the momentum and the variance statistics) introduced a scaling term that tries to normalize Muon's updates. The key error here is "unit variance per param". This correction ignores the core design principle of Muon: it is designed for matrices. Work by Bernstein established that the average magnitude of matrix elements, similar to the Frobenius norm of a matrix, is not the right metric. Neural networks do matrix multiplications, and the right metric in this context is the spectral norm of the matrix (more on this below). As far as we can tell, this is where the scale-dependent ambiguity seems to enter the public lineage. “Rescaled Muon's weight updates to have unit variance per param” in this unit-variance rescaling post. This might be good enough for speedrun purposes, but creates trouble later.
First proof of scale (and instability): Moonlight
Moonshot AI's paper “Muon is Scalable for LLM Training” trains Moonlight, a 3B/16B mixture-of-experts model, on 5.7T tokens: the first large model trained with Muon. The authors added weight decay, and they change the scaling factor from Keller's in an attempt to make the element-wise update magnitudes of Muon comparable to Adam . This theme emerges again, element-wise scaling is not the right thing to compare for Muon. They tweak the scaling factor from Keller's implementation, which sets things up for scaling disaster (likely the reason for MuonClip). The Muon implementation is roughly 2x the compute efficiency of AdamW, at the tested scales, and the author's scaling analysis implies a 2x compute multiplier effect over AdamW.
Catastrophic instability: trillion-parameter Kimi K2 + MuonClip patch
Moonshot's Kimi K2 technical report scales the story to a 1T-parameter MoE model with 32B active parameters. The important part for us is the optimizer: MuonClip. The paper describes MuonClip as an improvement over Muon with a QK-clip technique to address training instability, and reports K2 pretraining on 15.5T tokens with zero loss spike.
It looks like a patch entering the lineage. If the scaling factor had preserved Muon's matrix geometry cleanly, it is not obvious why a separate clipping mechanism should have become central to the trillion-parameter recipe. Deepseek-V3 report training quite stably with a similar architecture using AdamW.
Other labs adopt it; variants multiply
Other large-model efforts start to orbit Muon. GLM-4.5 is a 355B-parameter model, and INTELLECT-3 is a 106B-parameter MoE model trained on top of GLM-4.5-Air-Base. Meanwhile, research variants appear: NorMuon adds neuron-wise normalization, while Dion replaces the Newton-Schulz step with power iteration to better fit sharded, distributed training.
Special shoutout to Dion: this one gets the scaling factor right. The implementation recognizes the scaling factor needed for hyperparameter transfer and scaling behavior, and uses a default intended to induce a consistent change to activation vectors across model size.
Ambiguity built into the major frameworks
Muon then starts becoming infrastructure. PyTorch 2.9 ships
torch.optim.Muon natively, while
Optax
carries a community Muon contribution. DeepSpeed and NVIDIA NeMo add support too: the
DeepSpeed guide exposes
separate Muon and Adam learning rates, and
NeMo-RL exposes
muon_scale_mode. Muon goes from custom trick to one-line option.
The PyTorch implementation makes the ambiguity explicit: it offers an “original” scaling option following Keller's implementation and a “match_rms_adamw” option following Moonshot's implementation. The documentation frames this as flexibility, but from our point of view it is the bug fossilized as API surface. Neither of those scaling factors satisfies the spectral conditions for feature learning. To read more about the spectral condition for feature learning, see this paper.
Our guess is that these issues, along with related problems described by Tilde Research in Aurora and Compositional Muon, have already been noticed by frontier labs, if they are using Muon at all. In practice, the frontier labs may have dialed in how to use Muon-like optimizers correctly a long time ago.
One learning rate, many shapes
The problem we are going to discuss with the current implementations of Muon is about the maximal update parameterization (µP). This was an influential scaling recipe which allowed LLMs to be tuned at small scales, and then the hyperparameters such as the learning rate be transferred directly to the giant models with much larger widths. At the moment, none of the implementations of Muon offers the correct µP version, which could be problematic for researchers trying to do hyperparameter transfer with Muon or apply it to other domains such as protein co-folding. Before we talk about Muon itself, we need to discuss what kind of behavior we want from a neural network as it trains, which is related to the core idea of µP.
What we want during neural network training
At a high level, a neural network is a long sequence of vector states being multiplied by matrices, with nonlinearities sprinkled between the multiplications. The vector might represent a token, an amino-acid residue, an atom, or any other object the model is carrying through its layers. The first thing we want is simple: the individual coordinates of those vectors should stay normal-sized.
If a vector has width N, and its entries are roughly the same size, say Gaussian-ish around
zero with order-one variance, then the vector magnitude is roughly √N. That is usually
true at initialization, and we would like training to preserve that scale. We also want the change in
activations after a training step to scale the same way: ||Δx|| should be roughly
√N, so the individual coordinate updates are nonzero rather than vanishing as the model
gets wider.
The point of using N is scaling behavior. We want to change the width of the model and keep the
same qualitative training dynamics. But activation changes are not a knob we turn directly. They are caused
by the weights. So if we want stable feature learning across widths, we need a condition on how the weight
matrices are allowed to change during training. This is where Muon enters.
What Muon is trying to do
Muon is designed to limit output perturbations in a gradient update: it updates a linear layer in a loss-reducing direction, subject to a constraint on how much the layer’s outputs are allowed to change. This turns out to be quite useful.
Neural networks are compositional. They have many layers. Each layer is trying to learn a good mapping between its input distribution and its outputs. This is hard to do during training, because your input distribution is changing after every gradient update as lower layers learn.
Normalization tricks such as LayerNorm and RMSNorm try to mitigate this problem by mapping the activations
back to a hypersphere of radius √n where n is the number of neurons in the
layer. This makes sure layer inputs remain well-behaved numerically and they don’t become too small /
big as the network grows. However, you can still be moving very fast on the surface of this hypersphere
during training if your weight updates are large.
Muon has a couple tricks to bound the change in the Root Mean Square (RMS) RMS is the square root of the mean of squared entries: \(\sqrt{\frac{1}{n}\sum_i x_i^2}\). It measures the typical size of a vector entry. of a linear layer’s outputs. Combined with the right LR scaling based on fan-in and fan-out Fan-in and fan-out are the input and output dimensions of the matrix, respectively. , Muon can give tight bounds on the RMS change after an optimizer step. This fan-out / fan-in based scaling is not quite right in popular Muon implementations. You get in trouble if your matrix is rectangular. Moonshot AI got in exactly this kind of trouble when they combined multi-head latent attention (from DeepSeek V3) + wrong Muon scaling.
To see this problem, I find it the most intuitive to reason with RMS→RMS norms as done in Jeremy Bernstein’s blog post on deriving Muon.
Think of a simple linear layer that produces the output \(\mathbf{y}\), and let’s reason about what happens element-wise to the outputs of \(\mathbf{y}\) after an optimizer step:
The optimizer step changes the weight matrix with an update \(\Delta \mathbf{W}\). The resulting change in the network output is:
We do not want \(\Delta \mathbf{y}\) to be too big after a weight update. If certain layers make very large jumps after every training step, every layer after them receives noisy inputs, which makes learning harder. A nice way to reason about this change is the RMS→RMS operator norm of a matrix, which is the maximum amount by which a matrix can increase the average entry-size of its inputs after the matmul:
The spectral norm Spectral norm is a linear algebra quantity that measures the maximum factor by which a matrix can stretch its input vector. \(\|\cdot\|_{*}\) matters here because the Newton-Schulz orthogonalization step normalizes the update so that this quantity is 1.
The RMS→RMS norm of \(\Delta \mathbf{W}\) gives an upper bound on the change in output:
This means that as long as \(\|\Delta \mathbf{W}\|_{\mathrm{RMS}\to\mathrm{RMS}}\) is bounded, the change in the layer outputs remains bounded too.
Now suppose autodiff computes the raw gradient \(\nabla_{\mathbf{W}}\mathcal{L}\). Muon applies a few Newton-Schulz iterations to orthogonalize the gradient before the update step. This gives us the update direction that Muon will use. Because the routine includes a spectral-norm normalization, that update has:
If we calculate the RMS→RMS norm of this update, it comes out to:
This is the move: the geometric correction. Newton-Schulz gives us an update with spectral norm 1, but the quantity we care about is RMS→RMS. For a rectangular matrix, those are not the same. The update has RMS→RMS norm \(\sqrt{\frac{\text{fan-in}}{\text{fan-out}}}\), so we add the reciprocal factor \(\sqrt{\frac{\text{fan-out}}{\text{fan-in}}}\) before applying it:
This update rule satisfies \(\|\Delta \mathbf{W}\|_{\mathrm{RMS}\to\mathrm{RMS}} \le \eta\), and hence \(\|\Delta \mathbf{y}\|_{\mathrm{RMS}} \le \eta\). In words: the update keeps the RMS change in the outputs of any linear layer bounded by the learning rate \(\eta\) The core idea of µP with optimizers like Adam is also to make sure the singular values of weight matrices and updates scale like \(\sqrt{\frac{\text{fan-out}}{\text{fan-in}}}\). See Jeremy Bernstein’s note. .
This \(\sqrt{\frac{\text{fan-out}}{\text{fan-in}}}\) scaling is not being done right in Keller’s speedrun implementation or Moonshot AI’s training.
Where implementations diverge
| Implementation | Scaling factor | What it does | Geometry |
|---|---|---|---|
| Keller / speedrun Muon | \(\max(1, \sqrt{\frac{\text{fan-out}}{\text{fan-in}}})\) | Downprojections are affected; the reciprocal correction is clipped when \(\text{fan-out} < \text{fan-in}\). | Not quite right |
| Moonshot AI | \(\sqrt{\max(\text{fan-in}, \text{fan-out})}\) | Something weird: equivalent to Keller only if fan-in is the same for all matrices in the network. | Even worse |
| PyTorch / Optax | Keller or Moonshot-style scaling | Exposes the ambiguity as a user choice, not including the correct version. | Ambiguous |
| Dion | \(\sqrt{\frac{\text{fan-out}}{\text{fan-in}}}\) | Applies the RMS→RMS correction directly. | Correct |
When does the scaling matter?
The first large-scale stress test: Moonlight
Soon after its proposal, Muon was shown to scale to LLM training by Moonshot AI, an artificial intelligence company based in China. They wrote a paper literally called "Muon is Scalable for LLM Training", in which the Moonshot team progress the field of open-source LLM research by introducing Muon as their optimizer. However, the paper makes a couple of modifications to Muon based on a bunch of assumptions that are demonstrably wrong. This added a theoretical blunder to Muon which has now made it into frameworks like PyTorch and Optax. We dedicate the rest of the blog to explain the mistake and suggest a correction, paraphrasing Jeremy Bernstein's work.
The crucial modification is their per-matrix rescaling. The authors write, “In order to maintain consistent update RMS among matrices of different shapes, we propose to scale the Muon update for each matrix by its \(\sqrt{\max(A, B)}\).” At first glance, this sounds close to Keller’s \(\max(1, \sqrt{\frac{\text{fan-out}}{\text{fan-in}}})\), but the two are equivalent only if all matrices have the same second dimension. Moonlight uses the DeepSeek-V3 architecture, and that definitely does not have matrices with the same fan-in everywhere: Multi-head Latent Attention uses up- and down-projections to compress the KV cache during inference. So the assumption does not even make sense for the architecture they are using.
The authors then report that all is not well with Muon over Adam: attention becomes unstable. This should not be surprising. The dodgy scaling factor distorts the learning-rate geometry of MLA, and the symptom shows up as attention-logit explosions. By our calculation, the MLA down-projection is updated around 5x larger than it should be with respect to the global scale, which, when combined with the corresponding up-projection and the rest of the attention block, could easily destabilize MLA.
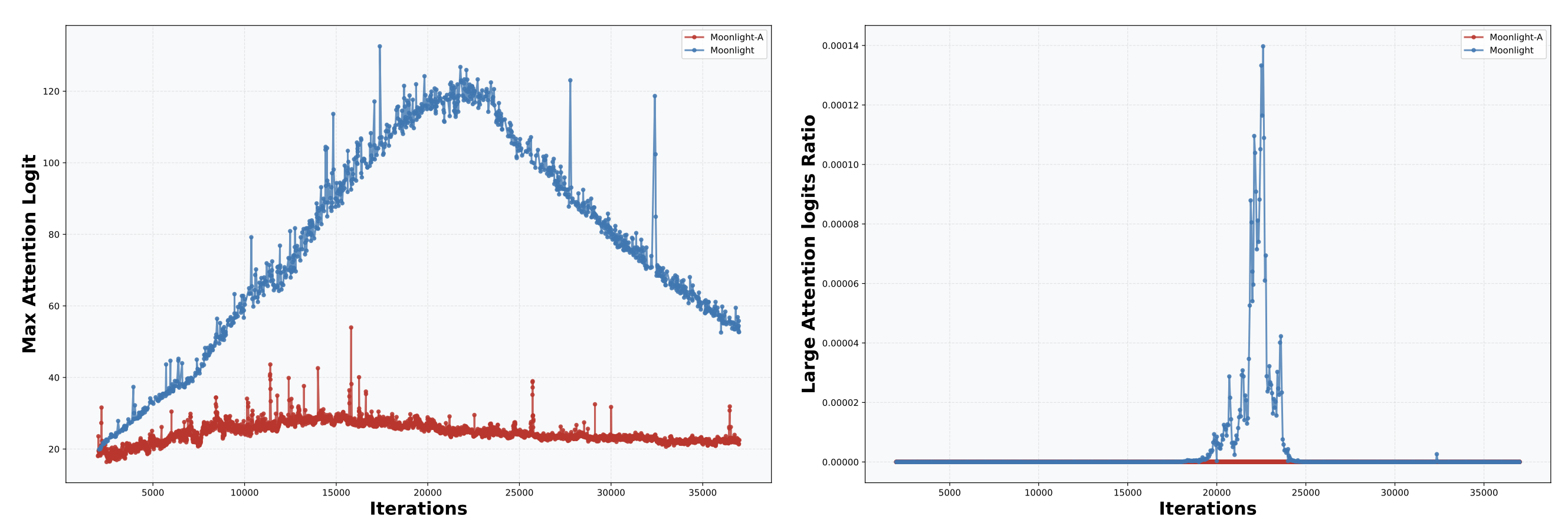
A CIFAR-10 learning-rate transfer test
To empirically confirm the failure of hyperparameter transfer with Moonshot AI's settings, we made a learning-rate transfer experiment using CIFAR-10. We constructed MLPs with a bottleneck in the middle of 6 layers to make sure we had rectangular matrices, and we trained models with 5 different optimizer settings: out-of-the-box Adam, µP learning-rate Adam, Muon with the correct \(\sqrt{\frac{\text{fan-out}}{\text{fan-in}}}\) scaling, Muon with \(\max(1, \sqrt{\frac{\text{fan-out}}{\text{fan-in}}})\) scaling, which gets the wrong learning rate in downprojections, and finally Muon with Moonshot AI’s proposed scaling \(\sqrt{\max(\text{fan-out}, \text{fan-in})}\). In a hyperparameter transfer experiment, the goal is come up with a recipe so that even when we scale up the size of the neural networks several fold, the optimal learning rate stays the same. If there is any drift, this would (1) require re-tuning of a larger network (2) if different layers prefer very different learning rates, the global learning rate is going to be an uneasy compromise between the layers.
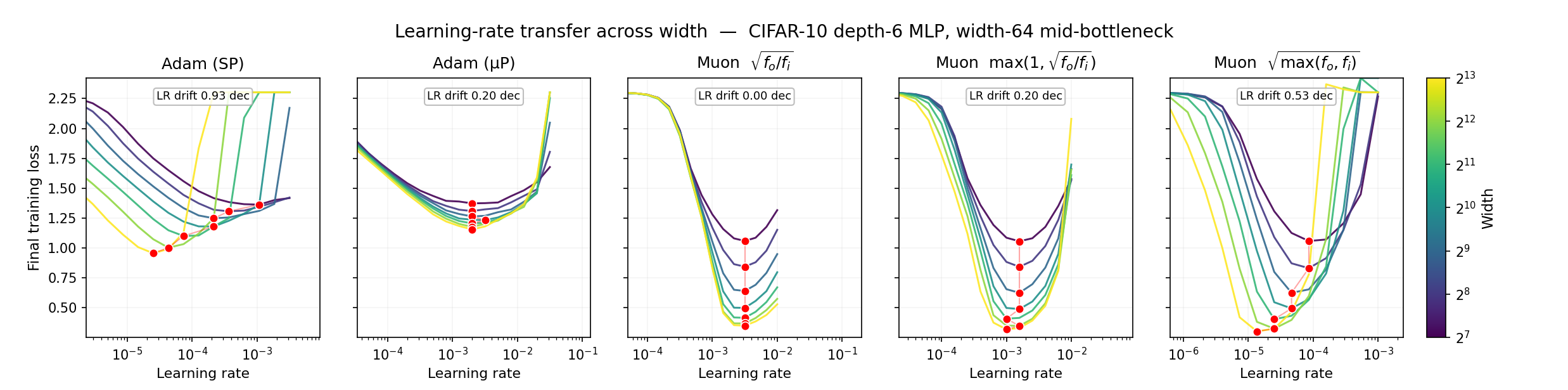
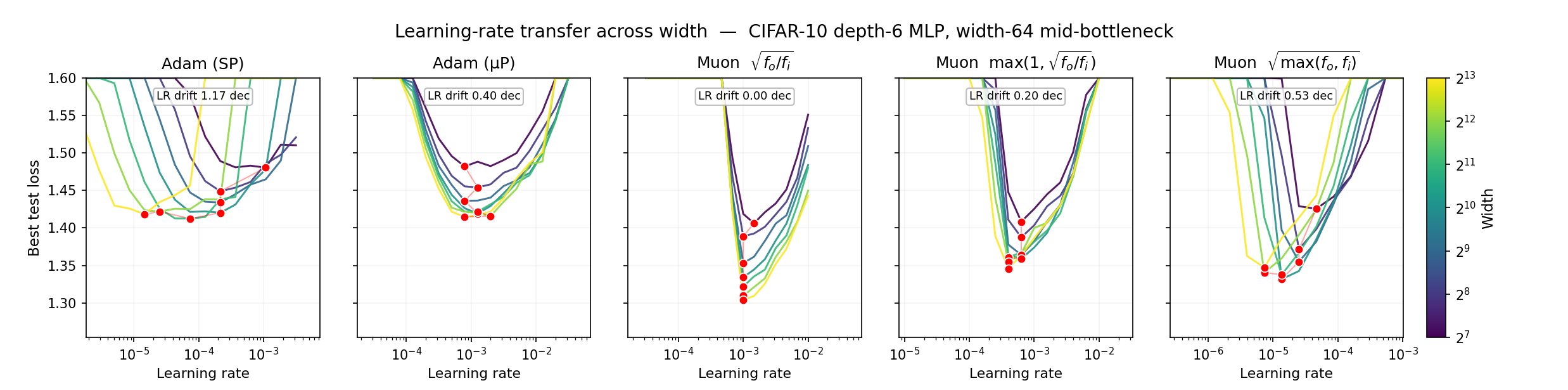
The results are quite striking. Perhaps the most noticable jump is from Moonshot AI's scaling factor to the correct maximal update parameterization. The correct version produces the lowest test loss at roughly the same learning rate at every width, whereas Moonshot's version systematically shifts to lower learning rates as we increase the width. The scaling factor proposed by Keller Jordan fares much better than Moonshot's, but it still drifts a little bit compared to the µP version. The drift in production settings would depend on the number of down-projection matrices and their down-projection factor. It's also noticeable that Muon with the correct scaling produces the lowest absolute test loss of any setting.
When everything gets the wrong learning rate
The implications for not getting the maximal update parameterization exactly right matters most if your network architecture has plenty of rectangular matrices. This matters for more experimental LLM architectures like DeepSeek-V3, with its multi-head latent attention logic, and for custom neural networks for biomolecular structure prediction, like AlphaFold3. To make the comparison concrete, we took a bunch of layers from the AlphaFold3 architecture and computed what the maximal-update (µP) scaling would prefer for the learning rate to be with respect to the global learning rate, versus what it actually ends up being. Here is the percentage error of the popular scaling rules relative to the correct \(\sqrt{\frac{\text{fan-out}}{\text{fan-in}}}\) factor for some rectangular projections in an AlphaFold3-style architecture:
| Projection | Shape | \(\max(1.0, \sqrt{\frac{\text{fan-out}}{\text{fan-in}}})\) | \(\sqrt{\max(\text{fan-in}, \text{fan-out})}\) |
|---|---|---|---|
| Diffusion atom decoder, token → atom | \(768 \to 128\) | +144.9% | +144.9% |
| Diffusion trunk single → token | \(384 \to 768\) | 0.0% | -29.3% |
| Diffusion atom encoder, atom → token skip | \(128 \to 768\) | 0.0% | -59.2% |
| Atom decoder, atom → xyz update | \(128 \to 3\) | +553.2% | +166.7% |
| Diffusion conditioning, pair concat → pair | \(256 \to 128\) | +41.4% | -18.4% |
| Diffusion transition down leg | \(1536 \to 768\) | +41.4% | +100.0% |
| Trunk pair init, single → pair | \(384 \to 128\) | +73.2% | +22.5% |
| Pairformer pair bias, pair → heads | \(128 \to 16\) | +182.8% | +15.5% |
| MSA pair-weight bias, pair → heads | \(128 \to 8\) | +300.0% | +63.3% |
| MSA single input → MSA channel | \(449 \to 64\) | +164.9% | +102.5% |
| Template pair → trunk pair | \(64 \to 128\) | 0.0% | -71.1% |
When the per-layer learning rates are wrong, the global optimum is going to be an uneasy compromise between all the layers of the network, and at lower precision training modes like bfloat16, could be potentially destabilizing for the network. We hypothesize that correct maximal update scaling with Muon could be a very good way of stably training very heterogeneous networks like biomolecular structure prediction models.
Conclusion
Muon is one of the most exciting algorithmic ideas proposed in deep learning. It is theoretically motivated, elegant, and beats strong baselines in speedruns. That almost never happens for optimizer ideas. It seems like as Muon moved from speedruns to large-model training runs to framework implementations, the community seems to have copied the most visible part of the method, the Newton-Schulz orthogonalization trick, while muddying the scaling rule that made the geometry meaningful. Square matrices hide this mistake, because most of the scaling rules agree there. Modern networks are rarely just square matrices; they are full of up-projections, down-projections, gates, heads, bottlenecks, and coordinate maps. Once those pieces start getting different effective learning rates, the global learning rate becomes an uneasy compromise: turn it down to save the hot layers and the cold layers stop moving; turn it up to wake up the cold layers and the hot layers destabilize. In that light, patches like MuonClip look less like new optimizer ideas and more like symptoms of a broken scaling rule. The good news is that the fix is conceptually simple: just restore the maximal-update geometry with the \(\sqrt{\frac{\text{fan-out}}{\text{fan-in}}}\) correction. This can be a one-line fix in libraries like PyTorch and Optax that implement Muon.
We are excited to see the impact of Muon and related ideas in the near future!
References
- Shazeer, Noam. 2020. “GLU Variants Improve Transformer.” arXiv:2002.05202.
- Bernstein, Jeremy. 2025. “Deriving Muon.” Blog post, March 7, 2025.
- Jordan, Keller. 2024. “Muon: An Optimizer for Hidden Layers in Neural Networks.” Blog post, December 8, 2024.
- Jordan, Keller. 2024. Unit-variance Muon rescaling post. X, October 11, 2024, 19:22 UTC.
- Liu, Jingyuan, Jianlin Su, Xingcheng Yao, et al. 2025. “Muon is Scalable for LLM Training.” arXiv:2502.16982.
- Kimi Team. 2025. “Kimi K2: Open Agentic Intelligence.” arXiv:2507.20534, revised February 3, 2026.
- GLM-4.5 Team. 2025. “GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models.” arXiv:2508.06471.
- Prime Intellect Team, Mika Senghaas, Fares Obeid, et al. 2025. “INTELLECT-3: Technical Report.” arXiv:2512.16144.
- Li, Zichong, Liming Liu, Chen Liang, Weizhu Chen, and Tuo Zhao. 2025. “NorMuon: Making Muon More Efficient and Scalable.” arXiv:2510.05491.
- Ahn, Kwangjun, Byron Xu, Natalie Abreu, Ying Fan, Gagik Magakyan, Pratyusha Sharma, Zheng Zhan, and John Langford. 2025. “Dion: Distributed Orthonormalized Updates.” arXiv:2504.05295; GitHub repository.
- PyTorch Contributors. 2026. “Muon.” PyTorch 2.9 documentation. Accessed June 10, 2026.
-
Optax Contributors. n.d.
optax.contrib.muon. Optax documentation. Accessed June 10, 2026. - Wang, Zhipeng, Guokai Ma, Peng Du, and Chi McIsaac. 2026. “Using Muon Optimizer with DeepSpeed.” PyTorch Blog, June 3, 2026.
- NVIDIA. n.d. “Muon Optimizer.” NeMo-RL 0.6.0 documentation. Accessed June 10, 2026.
- Yang, Greg, James B. Simon, and Jeremy Bernstein. 2024. “A Spectral Condition for Feature Learning.” arXiv:2310.17813.
- Dewulf, Alec, Dhruv Pai, Li Yang, Ashley Zhang, and Ben Keigwin. 2026. “Aurora: A Leverage-Aware Optimizer for Rectangular Matrices.” Tilde Research, May 5, 2026.
- Keigwin, Ben, Li Yang, Dhruv Pai, Yunzhe Zhang, and Alec DeWulf. 2026. “Towards Compositional Steepest Descent.” Tilde Research, June 1, 2026.
- Yang, Greg, Edward J. Hu, Igor Babuschkin, Szymon Sidor, Xiaodong Liu, David Farhi, Nick Ryder, Jakub Pachocki, Weizhu Chen, and Jianfeng Gao. 2022. “Tensor Programs V: Tuning Large Neural Networks via Zero-Shot Hyperparameter Transfer.” NeurIPS 2021; arXiv:2203.03466.
- Bernstein, Jeremy. 2024. Note on µP singular-value scaling. X, July 1, 2024, 11:58 UTC.
Citation
Please cite this work as:
Arda Goreci, "How Muon Lost Its Geometry",
Ligo Biosciences Blog, June 10, 2026.Or use the BibTeX citation:
@article{goreci2026muonlostgeometry,
author = {Arda Goreci},
title = {How Muon Lost Its Geometry},
journal = {Ligo Biosciences Blog},
year = {2026},
month = jun,
day = {10},
publisher = {Ligo Biosciences}
}